flowchart TD
A[Top words in topic] --> B["Salient word(s) selected"]
B --> C[Anchor formed]
C --> D[Adjustment using context and prior knowledge]
D --> E[Final interpretation]
Why Topic Models Don’t Mean What We Think They Mean
Topic models are statistical methods that automatically discover themes in large collections of text by identifying patterns of words that tend to appear together.
They represent each document as a mixture of topics, where each topic is a distribution over words. They are frequently used in qualitative content analysis, e.g., to see which topics occur in a set of documents, like historical archives.
A topic is just a list of words and frequencies. Assigning meaning to a list of words—a topic label—is usually done to distinguish topics. So the topic “apple, microsoft, google, innovation, startup” might be labeled as “tech” or “tech companies” or “silicon valley”, in order to capture some latent meaning behind the word list.
If a topic is “coherent,” we assume people will understand it in roughly the same way. If the top words look clean and related, we take that as a sign that the model has done its job. But that assumption hides something important: topic models don’t actually produce meaning, people do.
In our TACL paper Objectifying the Subjective: Cognitive Biases in Topic Interpretations, we wanted to understand what happens on the human side of that equation.
Interpretation Isn’t a Statistical Process
Most evaluations of topic models rely on the structure of the model itself, using word distributions, coherence scores, or lightweight human tasks like word intrusion (i.e., which word does not belong). These approaches implicitly assume that if the structure is good, interpretation will follow.
What they don’t really capture is the act of interpretation itself. So instead of asking whether topics are “good”, we looked at how people make sense of them. We ran user studies where participants didn’t just rate or label topics, they explained them. Those explanations turned out to be the most revealing part.
What became clear very quickly is that people are not making sense of topics as probability distributions. They’re not integrating all the words in some balanced way. They’re using cognitive shortcuts.
How People Actually Interpret Topics
Across participants, a consistent pattern showed up. People would latch onto one or two words, whatever stood out most, and use those as a starting point. From there, they would construct an interpretation by filling in the gaps, often pulling from prior knowledge or familiar categories. This is much closer to heuristic reasoning than to anything like statistical inference.
A Model of Topic Interpretation
The key step here is the anchor. Once a participant fixates on a word like “apple” or “startup,” that word shapes everything that follows. The rest of the topic is interpreted relative to it, not alongside it. That means two people can look at the exact same topic and walk away with different meanings, not because one is wrong, but because they started from different anchors.
This has even more importance when the topics are controversial (political topics, religion, etc.) or when user groups are not consistent (depth of subject knowledge, politics, other biases).
A Detailed Model
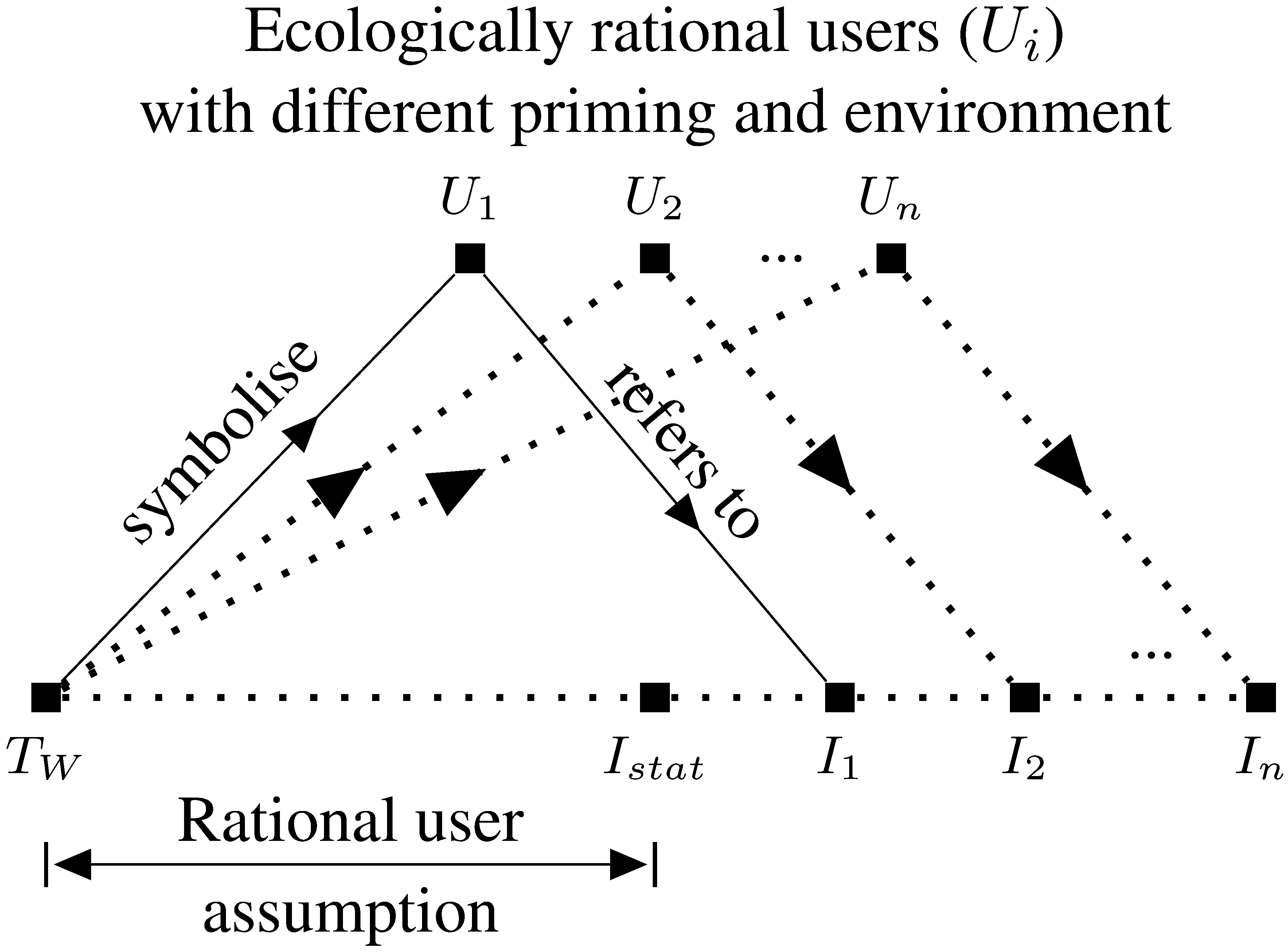
The more detailed version in the paper captures ecologically rational users with different priming and environment contexts.
The bottom axis shows a set of items/topics: the probable words of a topic, \(T_W\), the statistical coherence score, represented by \(I_{stat}\), and individual interpretations \(I_1\) through \(I_n\), which show how the individual labels change depending on the user. Multiple users \(U_1\) through \(U_n\) sit above this axis, each connected to items below via two types of relationships: “symbolise” (solid arrows) — from the topic words \(T_W\) up to the users, representing what the words symbolize to each user. “refers to” (dotted arrows) — from users down to items \(I_1 … I_n\), representing what each user takes the text to refer to. The bracket labeled “Rational user assumption” spans from \(T_W\) to \(I_{stat}\), suggesting that a naive/rational user model assumes text refers to a single statistical/canonical interpretation, whereas the full model accounts for the diversity across users (\(I_1 … I_n\)).
Interpretation as Judgment Under Uncertainty
Another way to think about this is that interpreting a topic is judgment. Participants are given a small set of signals (a list of words), and from that they infer what the topic might represent. There’s no single correct answer available to them, so they rely on whatever cognitive tools they already have: familiarity, category matching, salience.
This makes topic interpretation subjective, context-dependent, and sensitive to prior knowledge. And importantly, it means that coherence alone, the industry standard for assessing topic quality, doesn’t guarantee usefulness. A topic can look clean and still lead people in very different directions.
This follows from what is already known about human judgment and preference, e.g. as captured in Kahneman’s book “Thinking Fast and Slow”.
A Small Example
Take a topic with the words:
apple, microsoft, google, innovation, startup
From a modeling perspective, this is a straightforward “technology” topic. But in practice, interpretation depends on where someone starts. If “apple” stands out, the topic might be read through the lens of consumer tech. If “startup” anchors the interpretation, it might shift toward entrepreneurship. The same word list supports multiple plausible meanings.
What This Changes
The main takeaway for me is that we’ve been misaligned in how we evaluate topic models. We’ve focused on whether the model is internally coherent, when the real question is whether the interaction between model and user produces useful understanding. Once you look at interpretation as a cognitive process, a few things follow naturally:
- evaluation should be grounded in how people actually reason
- interfaces matter, because they can guide or constrain interpretation
- biases aren’t noise—they’re part of the mechanism
If topic interpretation is shaped by (fallible, subjective, human) heuristics, then improving topic models isn’t just about better algorithms. It’s also about designing systems that work with, rather than against, how people think.
This could mean:
- surfacing multiple possible interpretations
- helping users explore alternative anchors
- designing evaluation methods that capture interpretation
Topic models give us structure, but they don’t give us meaning. Meaning emerges in the interaction between the model and the person trying to use it, and that interaction is shaped by all the quirks of human reasoning.
Topics and the Post-LLM World
Topics are very much a pre-GenAI artifact. They provided a scalable and statistically sound way to summarize documents. Coherence scores provided the appearance of rationality. But nowadays, with context windows expanding, it often makes more sense to put the text into an LLM and get the AI to find topics.
However, this still doesn’t address the problems we identified. There are reasons to think the way LLMs process text is similar to humans: they get confused with too much information1, or they anchor on irrelevancies, or small changes send them in widely different directions. We even call it an “attention mechanism”!
We should continue to challenge assumptions that underpin simplistic benchmarks like SWE-bench, and be very careful with the problems of dealing with bias at scale that LLMs bring.