When Writing it Down is Not Enough: the Era of Computational Notebooks
 |
This is a talk I gave recently at the UVic Matrix Institute for Data Science. This is about the rise of what I (and others) call computational notebooks. Notebooks are inherent to doing science. They have supported exploration, kept detailed track of what was tried, and archive historical analysis. I want to talk about how these notebooks, and this way of doing science, is shifting to a computational approach. I'll cover the pros and cons, and talk about the engineering concerns computational notebooks introduce. |
 |
We'll cover three main topics. One, what makes paper notebooks so effective. Two, I'll introduce computational notebooks. And finally, I'll talk about the tradeoffs inherent in moving to Computational notebooks. |
 |
Notebooks support description. They record what has happened in our investigations, like the combinations of reagents we tried, experimental designs that failed, or ideas and thoughts we had. |
 |
They help us to explore, recording where the knobs were set on our chromagraph, or the parameters for the learning algorithm. This is important for serendipitous discoveries like post-it notes, vulcanized rubber, or penicillin. |
 |
They explain, to others, but also to our future selves, how to replicate the results we obtained. |
 |
Notebooks are there when we need them. They are cheap, easy to use, and portable. Notebooks can be used on the moon, or underwater. They can suffer acid burns and food spills. |
 |
Now I'd like to walk through some examples of notebooks through the ages. This one is Leonardo. Famously written in mirror script to prevent copying. Demonstrates considerably more artistic skill than most scientific notebooks, I'm guessing. |
 |
A valid question is what distinguishes, say, a chemist's notebook from that of an artist or musician. I guess my answer would be that there is no useful distinction in general. I think the explorations of a good scientist are just as creative, just as abductive, as those of musicians and artists. The notebooks capture the ideas and queries. In a way, the combinations and amounts of chemical reagents are no different than the sketches about light and perspective an artist might use. |
 |
Sir Isaac Newton. From the FitzWilliam Museum Cambridge; "this notebook preserves his thoughts on optics together with the sums he spent on laundry and the confession of past sins he could remember in 1662". This may be the first recorded instance of "Too Much Information". |
 |
Darwin---these note say "Case must be that one generation then should be as many living as now. To do this & to have many species in same genus (as is) requires extinction. Thus between A & B immense gap of relation. C & B the finest gradation, B & D rather greater distinction. Thus genera would be formed. ---bearing relation". Recall that Darwin was on a 2 year voyage around the world on the Beagle - with no wifi! And his notes + specimens would have to form the basis for his future work. No going back to the Galapagos to refresh your memory. Here notebook is used as replication. Contrast these type of field notes with the notes taken in the laboratory; in the lab, all the "subjects" are still present, and we need to recapture their proportions. In the field, we are describing what already is, and we need to capture that unchanging state (unchanging in human terms). |
 |
Marie Curie. If you look closely you can see the purple glove of the handler. Apparently her notebooks remain radioactive years later, so when you are knee deep in data and stressing out, remember that at least you are not being irradiated (on the other hand she won 2 Nobel Prizes in 2 different disciplines!) |
 |
Einstein. Math people use notebooks too! Maybe chalkboards. And as we will see, a mathematician/polymath created one of the earliest computational notebooks (Stephen Wolfram). Is there a distinction again with math notebooks, artistic notebooks, and "pure" science notebooks? |
 |
Rosalind Franklin's description of the X-ray crystallography of DNA, doing the important work for Crick and Watson. In the book "Scientific Writing", the author Schimel makes the case that Franklin was snubbed by the Nobel committee because she created only information, and not knowledge. In other words, perhaps her notes were useful as repository, but without further analysis insufficient for being truly groundbreaking. Or, she was the victim of sexism and her notes were worthy of a Nobel in themselves. |
 |
Margaret Mead: She states that she is preserving general ethnological materials carefully so that they can be used by anyone with a knowledge of Polynesia. Her incomplete notes on the problem assigned her by her advisor, Franz Boas would be of no use to anyone else, however, "so I'm being as cryptic and illegible and brief as I like." The materials in the Library of Congress's Mead collection support this distinction. Contrast this with Darwin, also a field scientist, who was more positivist in philosophy. |
 |
Let's talk about the constraints notebooks we've seen impose. What do they prevent us from doing? |
 |
They are fragile. Archive and replicability require expertise. For example, there are entire fields dedicated to the archiving and preservation and study of notebooks from famous scientists. The Newton Project is dedicated to assembling all the works of Isaac Newton; an interesting anecdote is that when some of the papers were donated to Cambridge, a well-meaning archivist re-organized them into his own schema; thus destroying the potential 'meta-data' as to how Newton himself stored things. Even how you make notes could be relevant. This is obviously an issue with old, famous notebooks, but think about all the relatively unknown notebooks that will never be studied. |
 |
They burn and are necessarily fragile. For example, we no doubt lost many records in the Brazilian museum fire. But are digital notebooks - stored, as of now, in Unicode and JSON, at least for Jupyter, any more permanent? |
 |
They are idiosyncratic and personal. |
 |
This is an example of Leonardo's mirror script + shorthand. Besides handwriting, the lack of a standard form means every scientific notebook is highly idiosyncratic, providing employment for handwriting experts and translators, but making easy replication difficult. |
 |
Paper notebooks are static and immutable. |
 |
Unlike Doctor Who, we cannot travel in time. This is not a problem, always; it means we can see exactly what we wrote, when. But it means re-running an older analysis with new data is impossible. |
 |
So if paper notebooks are easily destroyed, highly idiosyncratic, and immutable, how can we improve on this? Let's talk now about computational notebooks. |
 |
A computational notebook is exactly a paper notebook stored digitally. It is a combination of text and scientific computer code, often Python, which can generate visualizations. A set of computer readable cells that aims to mimic the experience Mead, Galileo and others might have had. |
 |
This is a screenshot of a Jupyter notebook running in a web browser (meaning, on any device with a web browser, so phones, tablets, desktops...). |
 |
Computational notebooks have a dual heritage: these paper notebooks, and software development practices. |
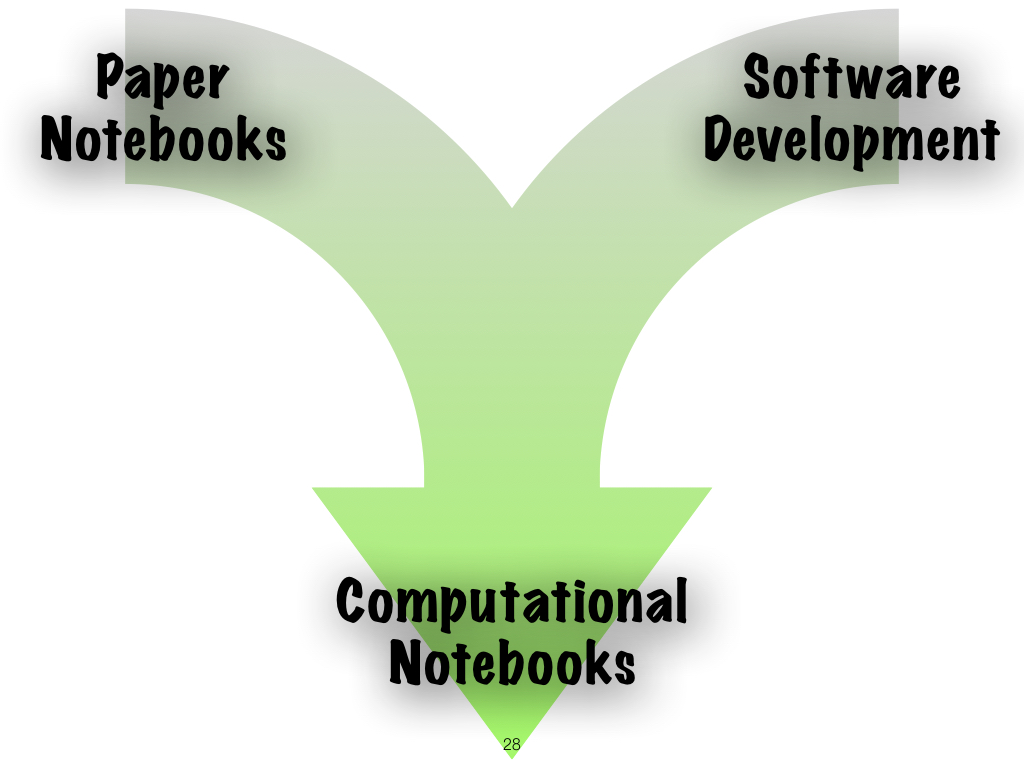 |
There are two parallel streams merging - the need for software programs to be maintainable by others, and therefore documented. Two, the notion of lab notebook as "stream of consciousness + reproducible artifact" |
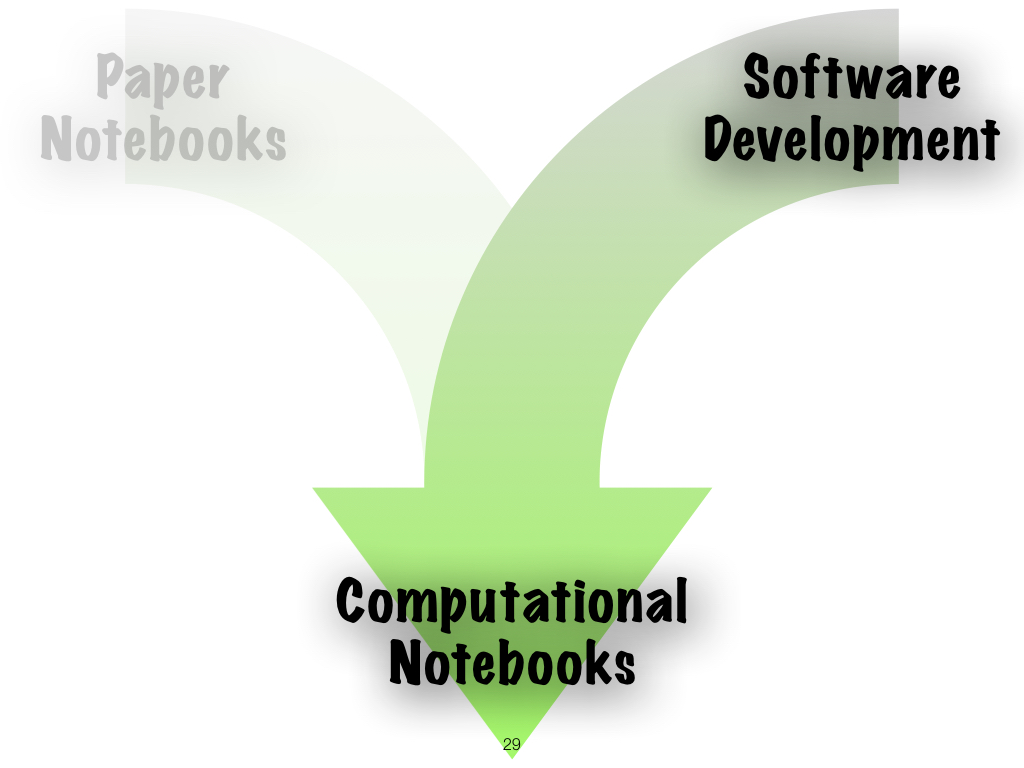 |
Let's look at the software lineage. |
 |
From the software lineage, computational notebooks get work that has been done on self-descriptive computer code. |
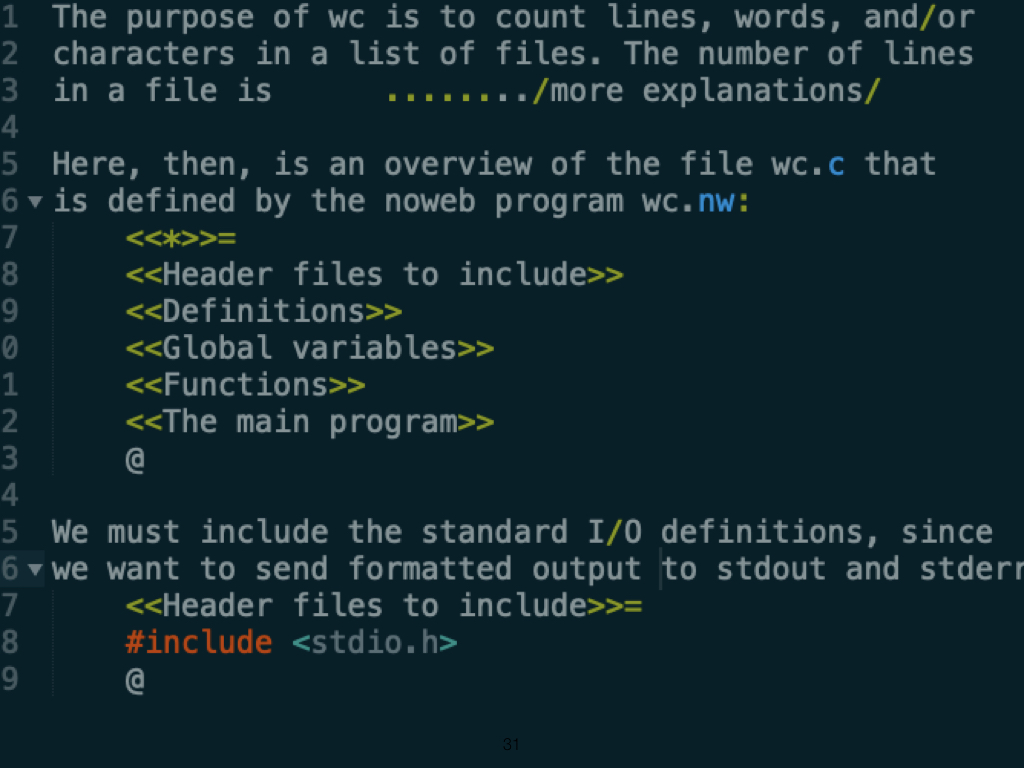 |
This is a screenshot of Donald Knuth's literate programming concept, from 1984. Literate programming mixes documentation and explanation with code, just like we see in modern computational notebooks. The problem Knuth was solving was the challenge of integrating software code with the documentation that described the purpose of that code. Even the earliest programs had a facility for annotating certain lines as comments, but literate programming was more than this. It was to end the (artifical) separation of design from code. This pedigree can be traced to various efforts over the years, mostly all unsuccessful, I would argue because the pudding in which the proof can be found is in fact the working bytecode that a program generates, and not human-readable comments. But you can trace several efforts here, arguably one of the most important being the notion of the "Read-Evaluate-Print" (REPL) paradigm behind interpreted languages like Perl, TCL, and now Python and R. |
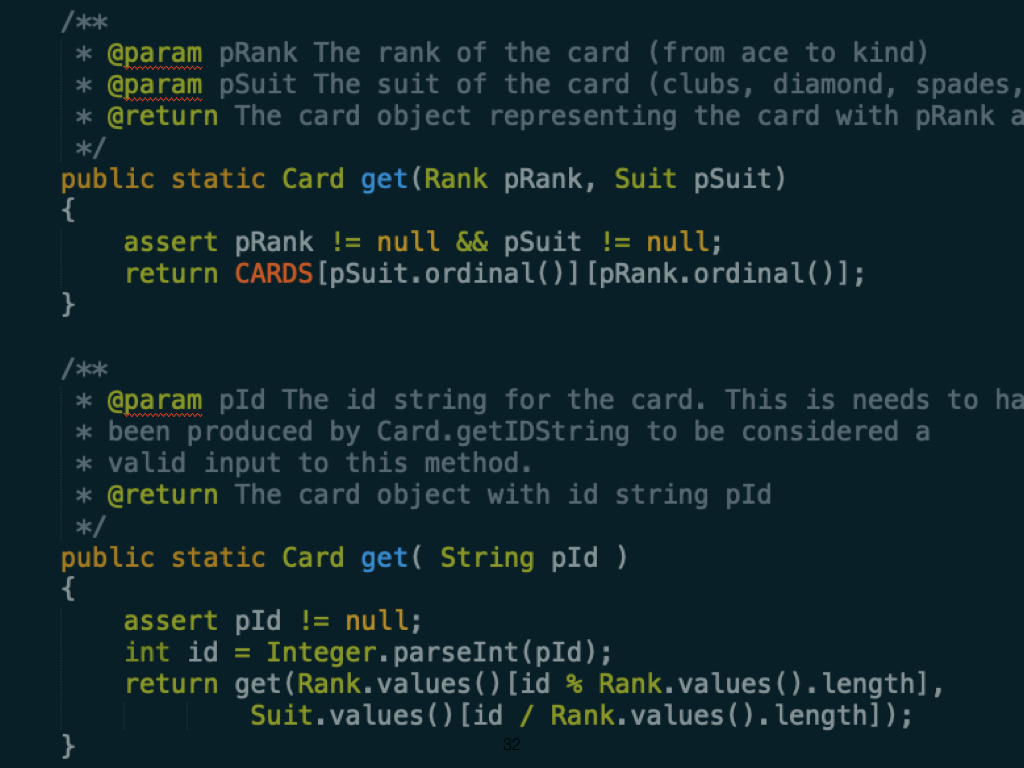 |
Similar efforts can be seen in modern languages. Here is an example from Java Docs. Annotations like @param are used to automatically generate documentation. One of my favourite quotes is "Any fool can write code that a computer can understand. Good programmers write code that humans can understand."" - Martin Fowler |
 |
Software engineering work has also given us the notion of interactivity. Not just run and see results, although we have made huge strides in this area, from the stories of walking your punch cards over to the timeshared "computer", then waiting a day to get the results. Read-Eval-Print loops, and interactive programming in Swift Playgrounds or block languages like Blockly. |
 |
Here is an interactive Swift playground allowing novice programmers to get rapid feedback about their program. |
 |
Brett Victor is a designer who has done a lot in this space, and I think more is to come. Here he describes a tool for programming that gives instantaneous feedback, with live debugging. As you change the variable on the right, the left side updates immediately. |
 |
What has of course really helped software development is the rich interchangeable set of software components we can leverage. The vision of reusable components is finally realized. |
 |
This screenshot shows dependencies for 1 of the Electron project's three manifest files. This is all code you do not have to write! |
 |
This applies even more so in scientific software. Here we see the ecosystem of Jupyter notebooks, showing all the components involved. |
 |
So from the software lineage notebooks get self-description, interactivity, and connectedness. |
 |
While programming software has become more interactive and repeatable, science has become more and more about software and computation, and so too have the tools to support that science. Many field scientists now spend much of their time at the computer, downloading data, processing data, and running analyses. |
 |
Recall our gallery of early notebooks. Clearly a main predecessor to computational notebooks is the rich history and lineage of textual notebooks. |
 |
The paper notebooks were:
|
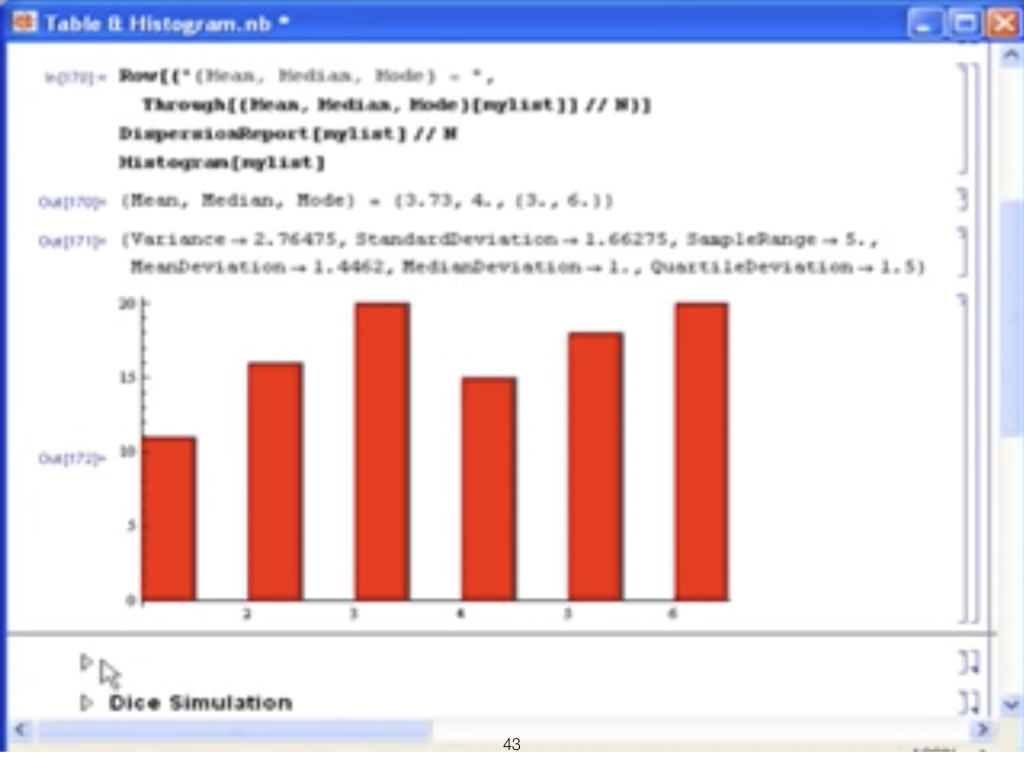 |
Mathematica, for example, has had the ability to inline graphics for decades. And in many ways - with simulations - open source alternatives are only now catching up (e.g, with Shiny from R). This is a screenshot from 2008 (Mathematica 6). Of course, the high cost of the tool and the closed nature of the language limited its popularity. |
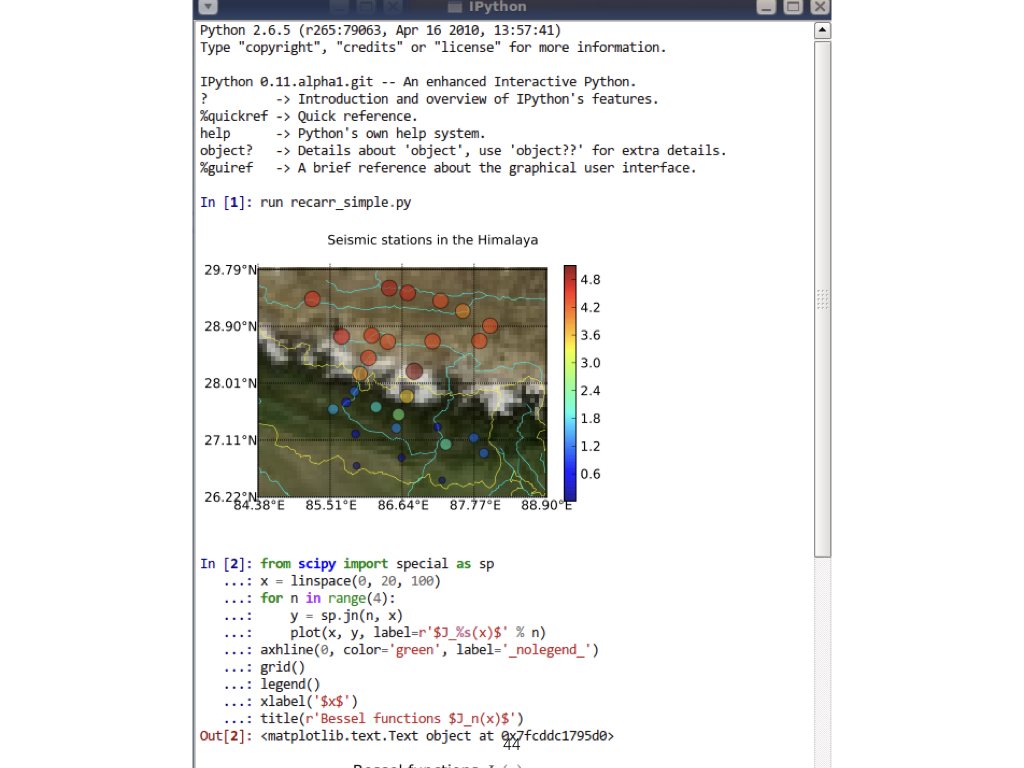 |
This is a screenshot of IPython 0.11 in 2010. It was created by Fernando Perez - physicist - and Brian Granger starting in 2001. In 2014 this was spun off into Project Jupyter, for Julia, Python, R, as a way to avoid his thesis. |
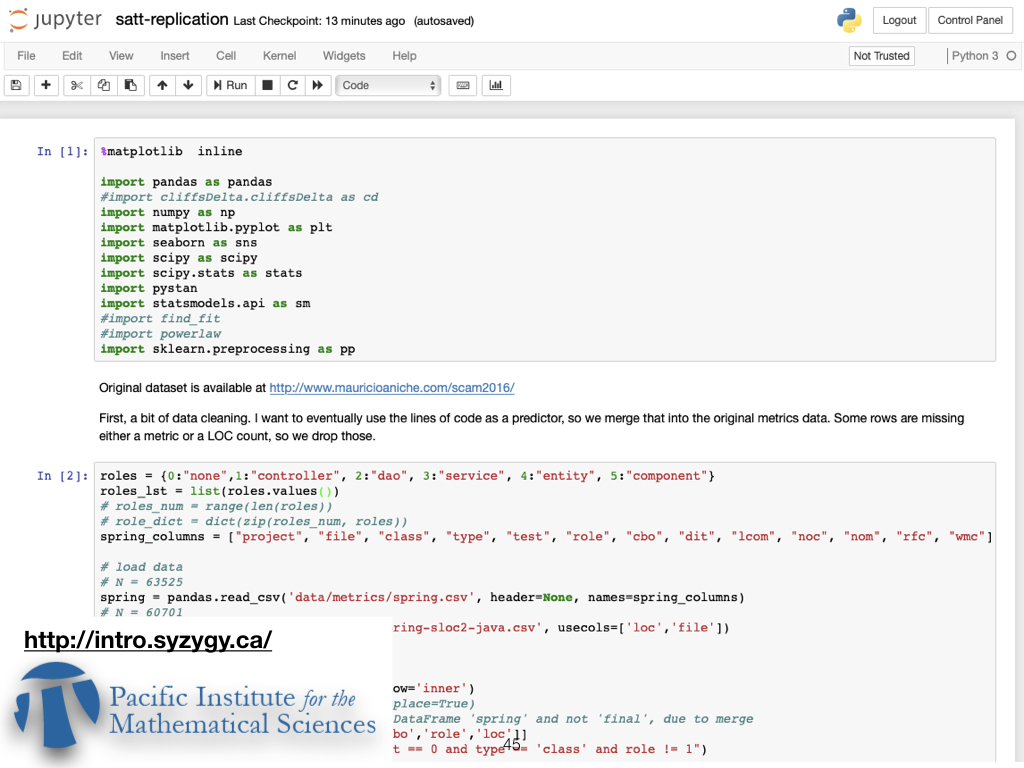 |
This raises the question... what is the computational notebook equivalent to Newton's diary? In the actual talk I gave a short demo of the Pacific Institute for Math's http://syzygy.ca Jupyter service. |
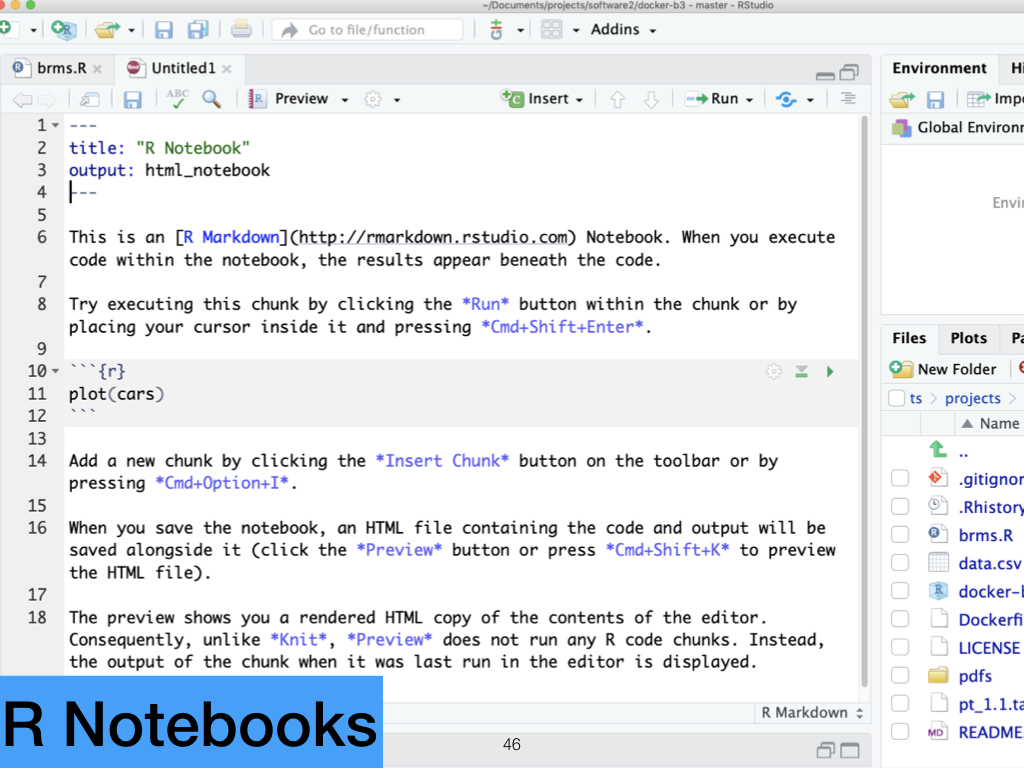 |
Similar capabilities exist with R Studio and R Notebooks. |
 |
Computational notebooks are descriptive, interactive, and connected. You get narrative (in this case, with Markdown text), you get the results of your typing with rapid feedback on changes (conditional on what you are trying to do, of course), and a huge ecosystem of related libraries. |
 |
One exploding area of notebooks is for data analytics in the enterprise. In particular, companies like Microsoft, Amazon Web Services, IBM and Netflix, among others, have talked about making notebooks the front-end to more complex machine learning pipelines, storing parameters, and so on. Tools like NTeract are trying to make the notebook experience more intuitive (e.g. drag and drop). This is actually involving a 3rd role, that of Data Engineer, as several researchers, including Rob Deline at Microsoft have pointed out. |
 |
Adam Rule has done some interesting descriptive analysis of notebooks. I encourage you to check his website for the details. My takeaway was that there was a lot of what I would call, for lack of a better term, "uninteresting notebooks", either cloned, or one-offs. |
 |
So I've talked about these different kinds of notebooks, and hopefully by now you see how powerful computational notebooks are. But I think there are some key aspects we really need to keep in mind. |
 |
The challenge as notebooks see more and more use is to balance their dual heritage in software and science, and in particular, support exploration without necessarily ignoring engineering concerns. |
 |
The worry I have is that notebooks are making replicable software really hard to write - much harder than writing code in Python or Fortran. And we already have enough problems getting people skilled up in these areas! I think the takeaway message then is this. In the old days Newton, Franklin, and Mead never anticipated their personal notes and diaries would be used for replication, or out of context propaganda campaigns. The trouble is digital notebooks are absolutely going to be used for replication! We have already seen what can happen when software you never thought would be looked at, gets looked at by your well-funded enemies. Notebooks are merging this world of experimentation and prototyping with the world of reproducible, high quality software, and those two worlds have very different aims. The story thus far then is that notebooks like Jupyter have been fantastic for prototyping and self-talk, but hard to use for replication and sharing. The Reinart-Rogoff problem was a bad calculation in an Excel spreadsheet, leading to incorrect conclusions in their paper. |
 |
The flip side of the Reinart-Rogoff problem is that Excel is staggeringly popular. For good reason. And yet, research shows that Excel is typically full of errors (e.g., you might overwrite a formula). Dr Felienne Hermans has studied this in detail. |
 |
Data scientists have been discussing this tradeoff of engineering and exploration. In this Twitter exchange, Graham Lea argues data science--what I call exploration--does not need engineering. Joel Grus, a software developer, strongly disagrees. I think from a software perspective, one extremely common problem is software that was written as a one-off, prototype exploration, that ends up becoming the production backbone of the entire enterprise. It is surprising how often developers don't expect their code to be around 20 or 30 years from now. |
 |
We need to understand, within some context of use, where we fit on a continuum. This will change with time, and with importance of the project. |
 |
The Square Kilometre Array project (SKA) is an interesting example. Here is the Jodrell Bank radio-telescope, one of the world's first. This telescope was also used to verify the general theory of relativity. |
 |
Another paper notebook, this one captures the discovery of pulsars by Jocelyn Bell Burnell. |
 |
The SKA will be dramatically different than the one Dame Bell used. This new telescope will connect thousands of antennae to look back to 300k years after the Big Bang. It will be enabled by extremely capable software. It is expected to process more data than entire internet in 2020. |
 |
Some of the software capabilities include
|
 |
Currently, SKA is being designed by a few software engineers, like me, but mostly by people who have built this stuff in the past, including physicists and astronomers. But the notebooks---the right side---are not being used for building the telescope. Actually, the learning from the notebooks---the results obtained---will inform many future projects. For example, a PhD student who devises a better data processing pipeline stands a good chance of seeing that code build or be incorporated into later telescopes. In the same way, climate model exploratory code - what does this model of cloud formation do - quickly gets built into the main model product. SKA and similar projects have to balance this dichotomy of scientific inquiry and exploration, with a need for highly capable, engineered software. |
 |
Now I'm obviously biased, as a software researcher :) But this is exactly the problem that has bedevilled scientific software since the beginning. The code you write as a grad student is still code! It gets used! It informs policy decisions. The fact Netflix, for example, uses notebooks as a front-end to ML pipelines means major decisions are being made based on notebook results. Sure, experimenting on Kaggle problems is a largely individual and creative art, just like (say) Da Vinci's notebooks. But we rapidly progress from "here's a neat model" to "model now making credit scoring decisions". Data science creates software; software gets used. |
 |
This is even more true in organizations and IT projects. Consider a project to improve hiring outcomes. This is a reasonable objective: it could save money and time if the best people were identified earlier in the process. A possible course of action is to form a data science team to examine the data collected on hiring so far. The team might train a classifier on the resumes or applications submitted, and suggest this will pinpoint the best candidates. At this point, we are in the exploratory setting; various algorithms and parameters are tried until the "best" one is found. Now the pendulum swings to software engineering, because the algorithm---the analysis pipeline, really---is put into production. Our organization needs to support both the exploratory phase as well as the production phase, and different tools apply for both. Furthermore, this is clearly not just a technical challenge, but a managerial pone as well. The biggest issue is the need to consider whether your analysis pipeline is truly producing fair and ethical results (which so far, has not been the case). |
 |
The notebook as we know it---I've been using them for about 5 years now---has gotten vastly better. Tools like those from Netflix, IBM, etc will only make things nicer. But for the end user, it's all a bit chaotic. To me it seems like the early days of software development, with a plethora of standards and languages, and no clear consensus. This will of course change. But there seems to be some clear problems that will have to be addressed, and my students and I are actively working on some of these. |
 |
The first issue is that of parameters and configuration settings. What are the parameters? Where are they located in the notebook? What libraries and versions are we using? The ongoing challenge of managing environments with tools such as Conda or virtualenv are only magnified when we add another layer on top. |
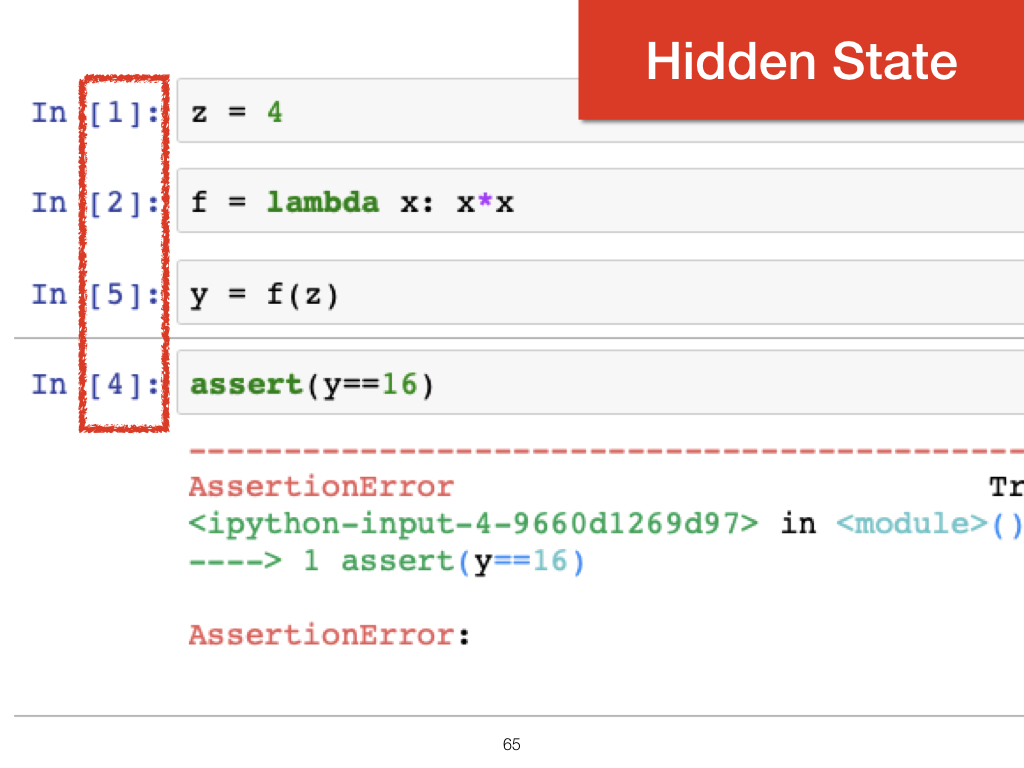 |
The second challenge is that of hidden state. When we run a program with the Python interpreter, it runs all the code it needs to. But in a notebook, the approach is more atomic. We run cells in any order we choose, and the dependencies between them, such as loading or cleaning data, are invisible. This has potential to cause errors, but also more subtle problems, such as depending on outdated data sources. |
 |
Our third challenge is not unique to notebooks, of course. Who hasn't worked on paper-2-v3-ne-final.docx? But think about this in the context of the beginning of the talk. What is the Marie Curie radioactive version of Jupiter notebooks? What will the Nobel prize winner of 2050 be using? How do we archive and store notebooks? How can our standard version control tools, developed for source code, work with the exploratory paradigms of notebooks? |
 |
Our fourth challenge is about testing and modularity. This is really about moving the science workflow into the software engineering pipeline of continuous integration and testing. Good modularity means parts of our workflow are easy to replace as needed, instead of existing in a single JSON textfile with a bunch of imports. These are lessons the software world has learned --- painfully --- over many years now. |
 |
The final problem is about education. Where and when do these practices get disseminated to students? Here in CS we use notebooks in the data mining course, but likely there is little time to explain best practices for notebook management. How do we teach notebooks in the context of software carpentry and reproducible science, if concepts like version control, package management etc are already foreign concepts? The real question is whether (data) science is about creating software? |
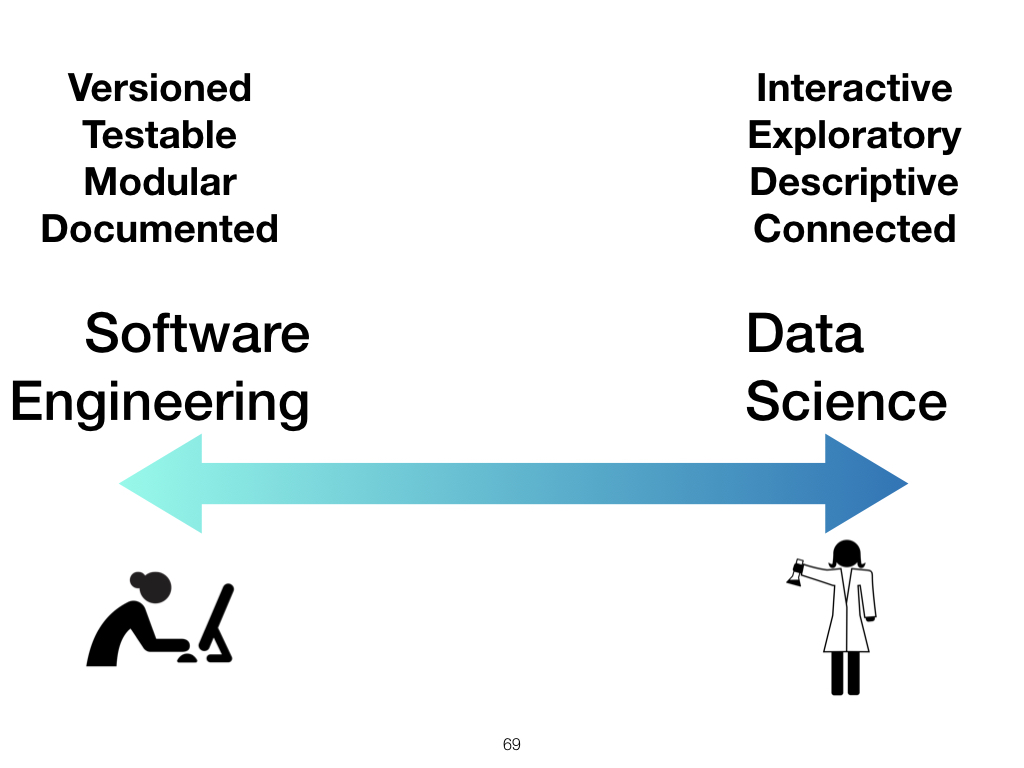 |
As we move into the data science age, the software 2.0 age, we need to keep this continuum in mind. This axis runs both ways, in my view. Software engineering gets more to the right, and data science moves more to the left. That is, software will become more data science, and data science more software engineering. |
 |
This is an exciting time. Computational notebooks have become connected, replicable, interactive replacements for paper notebooks, but many open questions remain! If you would like to pursue research in this area, please get in touch: neil@neilernst.net |
Links and Sources
- Kery et al. "The Story in the Notebook: Exploratory Data Science using a Literate Programming Tool", CHI 2017
- Adam Rule, Aurélien Tabard, James Hollan, "Exploration and Explanation in Computational Notebooks", CHI 2018
- Kery and Myers, "Interactions for Untangling Messy History in a Computational Notebook", VLHCC 2018
- Kim et al., "The emerging role of data scientists on software development teams", ICSE 2016
- Kim et al., "Data Scientists in Software Teams: State of the Art and Challenges", TSE 2017
- Begel and Zimmermann, "Analyze this! 145 questions for data scientists in software engineering", ICSE 2014
- Don Knuth, Literate programming. The Computer Journal, 27, 2 (Feb. 1984), 97-111.
- Wilson et al., Good enough practices in scientific computing, PLoS CompBio 2017
- James Somers, "The Scientific Paper is Obsolete", Atlantic, 04/18
- Steven Wolfram, "What is a Computational Essay", November 2017
- Netflix, "Notebook innovation at Netflix", Aug 2018
- Joel Grus, "I Don't Like Notebooks", Sept 2018 (JupyterCon)
- Yihui Xie, "The First Notebook War", Sept 2018